前回の「文字コードについて」では、URL のヒミツ(っていうほどでもないけど)をすこし覗いてみた。なんだかよくわからない文字がごにょごにょって書いてあるアレ。きょうはアレをもう少し見ていこう。
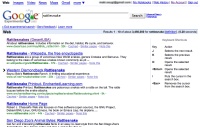
この記事を書くのに使っているパソコンは、Macintosh PowerBook G4。ブラウザは、Firefox 2.0.0.4(ウェブブラウザのひとつ)の日本語版。ブラウザの右上に検索プラグイン(ここに文字を入力すると、選択されているサービスで検索できる)がついている。そのプラグインから Yahoo! JAPAN を選択。「東海林さだお」と入力し、検索実行。すると、Yahoo! JAPAN のウェブ検索結果が表示される。そのときの URL は、
http://search.yahoo.co.jp/search?p=%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A&ei=UTF-8&fr=moz2&rls=org.mozilla:ja-JP:official
こんな感じ(もしかしたら途中で切れてるかも……)。これを細かく分解して見ていこう。分解のカギは、「?」と「&」。
- http://search.yahoo.co.jp/search?
- p=%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A
- ei=UTF-8
- fr=moz2
- rls=org.mozilla:ja-JP:official
読みにくくなるので「&」は省略したけど、こんな感じ。前回の記事を読んだ人はわかると思うけど、「%E6%9D%B1%E6%B5%B7%......」の意味するところは検索文字列に相当するもの、「ei」が検索文字列の文字コードってこと。これを上から順に翻訳していくとこんな感じ。
- http://search.yahoo.co.jp/search?
- これから「http://search.yahoo.co.jp/」の「search」というプログラムに問い合わせをしますよ
- p=%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A
- 検索文字列(p)は、「%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A」ですからね
- ei=UTF-8
- 検索文字列の文字コード(ei)は、「UTF-8」ですよ
- だから、「%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A」は「東海林さだお」って読めるでしょ
- fr=moz2
- 検索文字列がどこから入力されたのか(fr)って言うと、「moz2」ですよ(Firefox 2 のこと? あるいはその上位カテゴリ)
- rls=org.mozilla:ja-JP:official
- これ、なんだろ? 日本語版の Firefox のオフィシャルプラグインからの入力ですよってことかな?
つまり、Yahoo! JAPAN のウェブ検索プログラムに、なんだかんだと条件を指定しているということがわかるだろう。ユーザの意識に残っているものといえば、「東海林さだお」という検索文字列だけなんだけど、Firefox の検索プラグインを使うという行為により、検索プラグインに仕込まれているいくつかの情報がセットで送られているということだ。
Firefox の検索プラグインは、XML 形式で記述されているけど、その中身を見てみると……
<url type="text/html" method="GET" template="http://search.yahoo.co.jp/search">
<param name="p" value="{searchTerms}">
<param name="ei" value="UTF-8">
<mozparam name="fr" condition="pref" pref="yahoo-fr-cjkt">
<param name="rls" value="{moz:distributionID}:ja-JP:{moz:official}">
</url>
……こんな感じ(関係のある部分だけ抜粋)。{ } で囲まれている部分は、変数。例えば、{searchTerms} は検索文字列、{moz:distributionID}、{moz:official} あたりは、Firefox の規定値を参照することになっているものだろう。HTML を書いたことがある人ならわかると思うけど、FORM の記述方法にとても似ている。その書き方に無理に翻訳すると……
<form method="GET" action="http://search.yahoo.co.jp/search">
<input type="text" name="p" value="{searchTerms}">
<input type="hidden" name="ei" value="UTF-8">
<input type="hidden" name="fr" value="moz2">
<input type="hidden" name="rls"
value="{moz:distributionID}:ja-JP:{moz:official}">
</url>
……こんな感じだろうか(mozparam のところはちょっと手抜きした)。「input」は、文字どおり入力文字列を受け付けるタグ。その中でも「type="text"」となっているものは、ユーザの画面上にテキスト入力欄が表示される。それに対して「ei」と「fr」、「rls」は「type=hidden」なっている。「hidden」で送信されるものは、ユーザの画面上には表示されない。なので、ここはユーザの意志と無関係に規定値などが記入される。用途はさまざま。これによって、プログラムの挙動が変わったりすることもあれば、一見何も変化の起きないこともある。今回の例で言えば、「fr」と「rls」はユーザに対しては特に大きな役割は果たさない。おそらくクエリ分析に利用されるもの(どこからリクエストが来たかを判定するとか)。なので、それらを削っても、ユーザとしては得られる情報は同じもの(少なくともそう見える)。
http://search.yahoo.co.jp/search?p=%E6%9D%B1%E6%B5%B7%E6%9E%97%E3%81%95%E3%81%A0%E3%81%8A&ei=UTF-8「hidden」の項目がユーザの画面やプログラムの処理結果に影響を与えるかどうかを知るには、どうすればいいかということになるとすこし難しい。ひとつひとつ試してみるしかない。URL 欄に表示されたものをちょこちょこいじってみる……ということになる。
FORM で重要なのは、どんな情報をユーザから受け付けて、どんな情報を補助情報(ユーザの入力に委ねないもの)として送信するかということ。補助情報は、「hidden」で送信される。
もうひとつ重要なことがある。それは、「GET」と「POST」。さっきの例で言えば、
<form method="GET" action="http://search.yahoo.co.jp/search">
…で、「method="GET"」となっている。「method="GET"」であっても、「method="POST"」であっても、データがプログラムに送信されるのは同じなんだけど、送られ方がずいぶん違う。Yahoo! JAPAN のウェブ検索プログラムが「method="POST"」で送信されたデータを受け付けるかどうかはわからないけど、それが受け付けられるとすると、
<form method="POST" action="http://search.yahoo.co.jp/search">
<input type="text" name="p" value="{searchTerms}">
<input type="hidden" name="ei" value="UTF-8">
<input type="hidden" name="fr" value="moz2">
<input type="hidden" name="rls"
value="{moz:distributionID}:ja-JP:{moz:official}">
</url>
での送信結果の URL は、
http://search.yahoo.co.jp/searchとなる。つまり、URL の後半部のごにょごにょがなくなってしまうわけ。そうなると、上の URL をクリックしてもらえばわかるけど、検索文字列を入力して送信した結果の URL なのにその URL を後で再利用しようと思っても、同じ画面はユーザに提供されない……ということ。例えば、Yahoo! JAPAN で「
吉祥寺 いせや」と検索した結果のページの URL をともだちに知らせてあげようと思っても、「
http://search.yahoo.co.jp/search」しか表示されないので、それをともだちがそれを受け取っても同じ検索結果画面を見ることができない。つまり、再現性がないというわけだ。フォーム送信するようなページは、「GET」にしておかないと、検索エンジンにインデックスされない……ということが SEO の文脈で言われたりすることがあるけど、これも「POST」で生成される URL の再現性のなさが原因。
じゃあ、なんでも「GET」だったらいいのかというとそうでもない。「GET」には、文字数制限や情報の秘匿性の脆弱さということがある。WWW のさまざまなお約束を策定している
W3C で規定されていたかどうかはわかんないけど、Microsoft の Internet Explorer だと、2083字(半角英数字)以上の URL は
処理できないようだ。
情報の秘匿性の脆弱さについては、ログインフォームを考えるとわかりやすい。ID やパスワードを入力して送信するというのがログインフォームの仕事なわけだけど、「GET」で送信するということは、URL に ID やパスワードがまるわかりの状態で流れてしまうということ。これでは情報流出のリスクがある。Yahoo! JAPAN は、「GET」送信のフォームが多いけど、ログインフォームはきちんと「POST」送信になっている(それに加えて、送信内容を暗号化するようにセキュリティサーバを利用している。「https」で始まる URL はセキュリティサーバで保護されていることの目安)。
<form method="post" action="https://login.yahoo.co.jp/config/login?"
autocomplete="off" name="login_form">
「GET」がよいのか、「POST」がよいのか、そのメリットとデメリットを考えていくのが大事。